The pricing ops stack for AI companies

The modern AI economy runs on a fundamentally different infrastructure than traditional software. Where legacy SaaS companies built billing systems around seats and subscriptions, AI companies must architect pricing operations stacks that can handle token-based metering, dynamic compute costs, and outcome-based value delivery. This shift isn't merely technical—it represents a complete reimagining of how software companies measure, bill, and monetize value.
According to research from Bessemer Venture Partners, AI pricing strategy differs fundamentally from traditional SaaS models, with companies moving away from access-based pricing toward models that price for outcomes and consumption. This transformation demands an entirely new category of infrastructure: the pricing operations stack purpose-built for AI's unique economics.
The stakes are enormous. Morgan Stanley Research estimates that nearly $3 trillion of AI-related infrastructure investment will flow through the global economy by 2028. Yet many AI companies struggle to capture value from their innovations, with some services reportedly losing $20 per user monthly (up to $80 for heavy users) despite charging $10 per month. The gap between infrastructure investment and monetization capability represents one of the most critical challenges facing AI companies today.
Understanding the Pricing Ops Stack: Core Components
The pricing operations stack for AI companies comprises four fundamental layers: metering, billing, configure-price-quote (CPQ), and monetization engineering. Each layer addresses specific challenges unique to AI economics while integrating seamlessly to create a cohesive revenue infrastructure.
Metering Infrastructure: The Foundation of AI Pricing
Metering forms the bedrock of any AI pricing operations stack. Unlike traditional SaaS where usage tracking might involve simple login counts or feature flags, AI metering must capture granular consumption data across multiple dimensions: tokens processed, API calls made, compute resources consumed, model inferences executed, and outcomes delivered.
According to Metronome's analysis of leading AI companies, metering infrastructure for the AI era requires real-time tracking capabilities with low-latency enforcement of dynamic entitlements. OpenAI's evolution illustrates this complexity—the company initially struggled with postpaid usage models where heavy users rapidly depleted costs via expensive LLM and GPU consumption. This led to a strategic shift toward prepaid billing with more sophisticated metering controls.
Modern AI metering systems track multiple value units simultaneously:
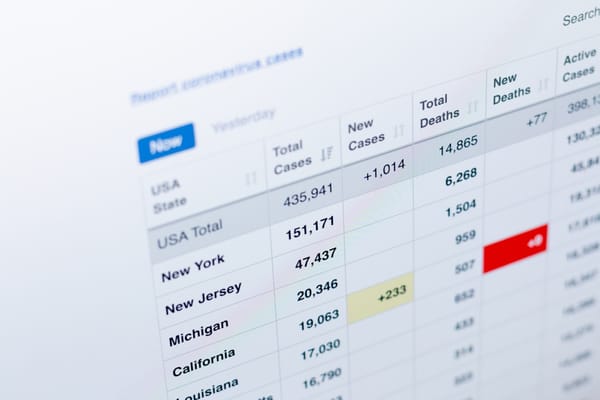
Token-based metering measures the fundamental unit of AI consumption. Anthropic charges $3 per million input tokens and $15 per million output tokens for Claude Sonnet, demonstrating how metering granularity enables precise cost recovery. Companies like Cursor implement threshold-based metering where 200,000 token jumps can double costs, requiring real-time tracking to prevent revenue leakage.
Compute-based metering captures the underlying infrastructure costs. With inference costs dropping 10x annually yet still representing significant expense, AI companies must meter GPU hours, CPU cycles, storage consumption, and network bandwidth. The industry has introduced new metrics like "tokens per watt per dollar" and Power Compute Effectiveness (PCE) to evaluate sustainable AI operations amid power constraints.
Outcome-based metering tracks delivered results rather than consumed resources. Intercom's Fin charges $0.99 per AI resolution, while Decagon implements per-conversation and per-resolution hybrid metering. This approach requires sophisticated event tracking that can attribute business outcomes to specific AI actions.
The technical challenges of AI metering are substantial. OpenMeter research identifies real-time metering for dynamic entitlements as particularly difficult, with mismatches between advertised and enforced limits causing cost overruns. Low-latency enforcement is essential but hard to scale when processing millions of API calls daily.
Billing Infrastructure: Managing Variable AI Economics
While metering captures consumption data, billing infrastructure transforms that data into revenue. AI billing systems must handle unprecedented variability compared to traditional SaaS subscriptions.
Traditional SaaS billing evolved around predictable recurring revenue—monthly or annual subscriptions with minimal variation. AI billing must accommodate dramatic consumption fluctuations, with per-user costs varying 10x or more based on usage patterns. This variability stems from AI's fundamental economics: the compute power behind large models burns through infrastructure budgets quickly, creating margin pressures that traditional billing systems weren't designed to handle.
Leading AI companies have adopted several billing approaches:
Usage-based billing charges customers based on actual consumption, aligning revenue with variable costs. Stripe Billing and Chargebee have enhanced their platforms to support usage-based invoicing integrated with AI providers for token-to-dollar conversion. However, pure usage models create customer friction through unpredictable bills, demanding transparency via real-time dashboards and alerts.
Hybrid billing models combine base subscriptions with usage-based components. Adobe's Firefly AI implementation demonstrates this approach—the company added Generative Credits as a usage layer atop subscriptions, bundling base usage with overages to balance predictability and monetization. According to Wing Venture Capital analysis, 41% of AI companies now adopt hybrid models, blending SaaS stability with AI flexibility.
Prepaid credit pools allow customers to purchase token allocations upfront, providing budget control while enabling flexible consumption. This approach has gained traction after OpenAI's experience with postpaid models, where lack of budget controls led to unexpected overages and customer dissatisfaction.
The billing infrastructure must also support sophisticated pricing mechanisms unique to AI:
- Tiered pricing with volume discounts (OpenAI's Batch API offers 50% discounts for non-real-time processing)
- Dynamic pricing that adjusts based on model version, processing priority, or time of day
- Multi-dimensional billing combining tokens, API calls, storage, and outcomes in single invoices
- Real-time balance tracking preventing service interruption while managing credit consumption
According to research from Deloitte, software companies are spending billions on generative AI integration, making sophisticated billing infrastructure essential to monetize these investments and avoid C-suite scrutiny over ROI.
Configure-Price-Quote (CPQ): Enabling Complex AI Deals
As AI companies mature beyond self-service models into enterprise sales, CPQ systems become critical infrastructure. Traditional CPQ platforms designed for seat-based software struggle with AI's unique requirements.
AI-specific CPQ must handle:
Outcome-based deal configuration where pricing ties to business results rather than user counts. Salesforce CPQ and Apttus have evolved to support configurations around ROI thresholds—for example, Leena AI's pricing based on ticket closures or EvenUp's per-AI-generated-package model. These configurations require cross-functional workflows aligning product, sales, and finance teams on value metrics.
Hybrid package assembly combining base subscriptions, usage allowances, overage rates, and outcome guarantees into coherent proposals. Sales teams need to size scalable contracts without complexity that confuses buyers. According to Bessemer's analysis, 65% of AI SaaS vendors now layer AI metrics on top of seat-based pricing, requiring CPQ systems that can model both dimensions simultaneously.
Usage forecasting and scenario modeling help customers understand potential costs under different consumption patterns. Given AI's variable economics, enterprise buyers demand projections showing costs at 10th, 50th, and 90th percentile usage levels. CPQ systems must integrate with metering data to provide realistic estimates based on actual consumption patterns.
Custom pricing rules accommodate the diverse pricing models emerging in AI. From per-token infrastructure pricing to outcome-based application pricing, CPQ must support multiple value metrics within single deals. Metronome's research with companies like OpenAI, Salesforce, and GitLab shows that leading AI firms organize dedicated pricing/packaging teams working within CPQ frameworks to enable rapid experimentation.
The integration between CPQ and downstream billing systems is particularly critical for AI companies. Unlike traditional software where quoted prices remain static, AI deals often include dynamic components that adjust based on actual consumption. CPQ systems must pass complex pricing logic to billing platforms that can execute it accurately at scale.
Monetization Engineering: The Strategic Layer
The most sophisticated AI companies treat monetization as a core engineering discipline rather than a finance afterthought. This represents a fundamental departure from traditional SaaS approaches.
Monetization engineering encompasses the platforms, practices, and organizational structures that enable rapid pricing experimentation and optimization. According to Metronome's analysis of leading AI companies, this discipline centers on several key principles:
Entity-first modeling defines customers, usage events, and billing entities before implementing pricing logic. OpenAI organizes monetization engineering into specialized pods: pricing/packaging strategy, monetization infrastructure, financial automation, and payments. This structure ensures pricing decisions flow from clear entity models rather than ad-hoc implementations.
Decentralized experimentation on centralized substrate allows product teams to test pricing innovations while maintaining system coherence. Rather than building separate billing systems for each product line, leading companies create governed foundations that support diverse pricing models. This approach prevents the architectural sprawl that plagued earlier SaaS companies.
Platform ownership and observability treat monetization systems as critical infrastructure requiring dedicated engineering investment. OpenAI runs post-change retrospectives and month-end reviews to automate failure detection, while Salesforce holds bi-weekly executive meetings aligning pricing with quotas and system capabilities. This operational rigor prevents billing outages that can devastate revenue.
Modular architecture with clear boundaries isolates metering, billing, and payment logic to prevent cascading failures. OpenAI fixed model-launch billing overload by separating concerns—when billing logic was embedded in product code, launches caused outages. The solution involved creating discrete services with well-defined interfaces.
The technical requirements for monetization engineering platforms include:
- High-throughput, low-latency processing supporting millions of metering events daily
- Real-time analytics providing visibility into consumption patterns, revenue trends, and margin dynamics
- Self-service controls enabling customers to set budgets, monitor usage, and manage spend
- Multi-environment support allowing different pricing rules for development, staging, and production
- Audit trails and compliance tracking all pricing changes and billing events for financial reporting
According to analysis from L.E.K. Consulting, traditional feature tiers rarely work when AI capabilities span multiple functions or create different levels of value for each customer. Monetization engineering platforms must support this complexity while remaining operationally manageable.
The AI-Specific Pricing Stack vs. Traditional SaaS
The differences between AI pricing operations stacks and traditional SaaS infrastructure extend far beyond simple feature additions. They represent fundamentally different approaches to value creation, capture, and delivery.
Economic Model Differences
Traditional SaaS economics center on near-zero marginal costs. Once software is developed, serving additional customers costs almost nothing. This economic reality enabled seat-based pricing where revenue scaled linearly with users while costs remained relatively flat, creating attractive unit economics.
AI economics invert this model. Each AI inference, generation, or interaction consumes real computational resources with measurable costs. According to Deloitte research, generative AI queries cost between 1 and 36 cents each, compared to fractions of a penny for traditional software operations. This fundamental cost structure makes seat-based pricing economically untenable for many AI applications.
The shift manifests in several ways:
Marginal cost alignment: AI pricing must track variable delivery costs much more closely than traditional SaaS. When Anthropic processes tokens through Claude, real GPU cycles are consumed with measurable electricity and infrastructure costs. Pricing operations stacks must meter this consumption accurately and bill accordingly to maintain margins.
Value decoupling from seats: AI often replaces human work rather than augmenting it, breaking the connection between user counts and value delivered. An AI SDR might handle lead qualification for an entire sales team, making per-seat pricing nonsensical. According to research from multiple sources, seat-based pricing adoption dropped from 21% to 15% in just 12 months as AI capabilities expanded.
Cost variability management: Traditional SaaS companies could predict infrastructure costs with high accuracy. AI companies face dramatic variability—heavy users might consume 10x or 100x more resources than light users. Pricing operations stacks must provide real-time visibility into per-customer margins to prevent unprofitable relationships.
Token Metering: The AI-Native Abstraction
Token metering represents one of the clearest distinctions between AI and traditional SaaS pricing infrastructure. Tokens serve as an abstraction layer bridging raw computational work (GPU cycles, memory allocation, network transfer) to customer-perceived value (content generated, questions answered, tasks completed).
Traditional SaaS rarely needed such abstractions. A CRM user either had access or didn't; a project management seat was binary. AI requires graduated measurement because value delivery varies continuously based on task complexity, model sophistication, and output quality.
Token-based metering enables several critical capabilities:
Transparent cost attribution: Customers can understand what drives their bills. Rather than opaque "compute units," tokens provide intuitive measurement—1,000 words of generated content consumes approximately X tokens. This transparency reduces billing disputes and enables better customer budgeting.
Flexible packaging: Companies can bundle token allowances into subscription tiers, offer prepaid token packs, or implement pure pay-as-you-go models. Stability AI demonstrates this flexibility with subscription plus usage pricing, while Notion and Canva use seat-based pricing with AI add-ons as bridges to usage models.
Multi-model pricing: Different AI models have vastly different costs. GPT-4 consumes more resources than GPT-3.5; image generation differs from text. Token metering allows single pricing operations stacks to handle multiple models with different token-to-dollar conversion rates.
Granular optimization: Product teams can analyze which features consume excessive tokens and optimize accordingly. This feedback loop between metering and product development doesn't exist in traditional SaaS where marginal costs are negligible.
The implementation complexity of token metering shouldn't be underestimated. Systems must track tokens across multiple dimensions (input vs. output, model version, processing priority), aggregate them accurately in real-time, and translate them into customer-facing metrics that drive purchasing decisions.
Compute-Based Billing Architecture
While traditional SaaS billing systems handle recurring charges and simple usage metrics, AI companies require infrastructure resembling cloud providers like AWS—sophisticated systems that can bill for diverse computational resources consumed over time.
Compute-based billing introduces several architectural requirements absent from traditional SaaS stacks:
Multi-dimensional resource tracking: AI workloads consume GPU hours, CPU cycles, memory, storage, and network bandwidth simultaneously. Billing systems must aggregate these resources accurately, often with different pricing for different resource types. A single AI inference might involve GPU processing, model weight storage, input/output data transfer, and result caching—each billable component requiring precise metering.
Time-based pricing variations: Compute costs vary by time of day, availability zone, and resource scarcity. OpenAI's Batch API offers 50% discounts for processing that can tolerate 24-hour delays, requiring billing systems that can apply temporal pricing rules automatically.
Performance tier differentiation: Premium models, faster processing, or guaranteed availability command higher prices. Cursor charges different rates for premium model access, requiring billing infrastructure that can track which tier handled each request and price accordingly.
Infrastructure cost pass-through: Some AI companies operate on thin margins, passing infrastructure costs through to customers with modest markups. This requires near-real-time cost data from cloud providers integrated into billing systems—a level of integration unnecessary for traditional SaaS.
The architectural pattern emerging among leading AI companies involves separating metering (data collection) from billing (revenue recognition) from payments (money movement). This modular approach allows each layer to scale independently and evolve as pricing models change without requiring complete system rebuilds.
API Monetization as Core Revenue
Traditional SaaS rarely monetized APIs directly—they were enablers for the core product, not revenue centers themselves. AI companies often generate majority revenue through API access, fundamentally changing pricing operations requirements.
API-first monetization demands:
High-throughput metering: Systems must track millions of API calls daily with minimal latency impact. Each call generates metering events that must be processed, aggregated, and billed. According to DevOps Digest analysis, APIs that generate downstream value require sophisticated tracking of revenue attribution across the customer journey.
Rate limiting and quota management: Unlike traditional SaaS where usage limits are soft guardrails, AI API quotas are hard constraints preventing cost overruns. Pricing operations stacks must enforce limits in real-time, provide customers visibility into remaining quota, and enable self-service quota increases.
Developer-focused billing UX: API consumers expect programmatic access to billing data, webhook notifications for quota thresholds, and automated billing alerts. This requires billing systems with robust APIs themselves—a meta-requirement where the billing infrastructure must be as developer-friendly as the product being billed.
Multi-tenant isolation: API customers often serve their own customers, creating nested billing relationships. An AI company might bill a customer who then bills their end-users. Pricing operations stacks must support this multi-level billing with clear cost attribution and margin visibility at each level.
The complexity of API monetization has driven companies like OpenAI to prioritize billing UX for control, with dashboards showing real-time consumption, spending projections, and budget alerts. This level of customer-facing billing sophistication was rare in traditional SaaS but becomes table stakes for AI companies.
Building the Modern AI Pricing Ops Stack: Vendor Landscape
The vendor ecosystem supporting AI pricing operations has evolved rapidly, with both established billing platforms adapting and new AI-native solutions emerging. Understanding the landscape helps companies make informed build-versus-buy decisions.
Metering and Usage Tracking Platforms
Several specialized platforms have emerged to handle AI-specific metering requirements:
Metronome positions itself as the monetization platform for the AI era, with customers including OpenAI, Anthropic, and other leading AI companies. The platform emphasizes modular architecture, real-time metering, and support for complex pricing models including usage-based, outcome-based, and hybrid approaches. Metronome's entity-first modeling approach aligns with best practices from leading AI companies.
OpenMeter focuses specifically on usage-based pricing challenges, providing real-time metering infrastructure that can track consumption across multiple dimensions. The platform addresses the metering accuracy issues that plague AI companies, offering low-latency enforcement of dynamic entitle